Using Benchmarking Infrastructure to Evaluate LLM Performance on CS Concept Inventories: Challenges, Opportunities, and Critiques
 Benchmarking 10 LLMs on a CS concept inventory identified that their responses reflected below average introductory computing students.
Benchmarking 10 LLMs on a CS concept inventory identified that their responses reflected below average introductory computing students.Abstract
BACKGROUND AND CONTEXT. The pace of advancement of large language models (LLMs) motivates the use of existing infrastructure to automate the evaluation of LLM performance on computing education tasks. Concept inventories are well suited for evaluation because of their careful design and prior validity evidence.
OBJECTIVES. Our research explores the feasibility of using an automated benchmarking framework to evaluate computer science (CS) concept inventories. We explore three primary objectives: evaluation of LLM performance on the SCS1 and BDSI concept inventories; informal expert panel review of items which had variations between LLM and expected student performance; and description of challenges with using benchmarking infrastructure as a methodological innovation.
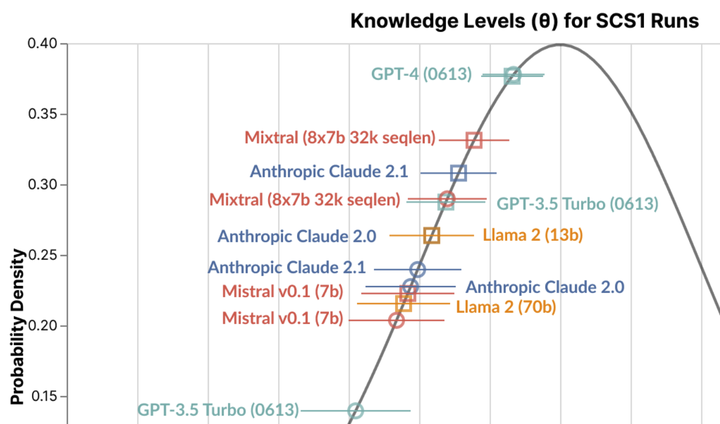
METHOD. We used the Holistic Evaluation of Language Models (HELM) framework to evaluate the SCS1 and BDSI against 10 LLMS with zero-shot and few-shot in-context learning: GPT (3.5, 4.0), Claude (1.3, 2.0, 2.1), Llama (7B, 13B, 70B), Mistral v0.1 7B, and Mixtral 8x7B. We used psychometric data from prior studies to measure knowledge levels for each LLM run. We then conducted an informal expert review to qualitatively explore how question design, CS content knowledge, and LLM design may explain differences between LLM and expected student performances.
FINDINGS. Our quantitative analysis found that most LLM response patterns reflected a below average introductory computing student with the SCS1 and did not fit the psychometric 2PL model for the BDSI. Our qualitative analysis identified that LLMs performed well on code infill questions, but poorly on nested conditionals, runtime analysis, and longer questions. We also identified several methodological challenges related to item security, translation, the structure when using HELM.
IMPLICATIONS. We consider the feasibility of using automated benchmarking as a methodology to support more reproducible, replicable, and rigorous investigations to understand the intersection of LLM capabilities, computing concepts, and assessment design. We also consider connections between psychometric approaches and LLM evaluations to inform the design of computing assessments that are more resilient to LLM advancements.